

Introduction
In this blog, we'll explore the versatile capabilities of Apache Spark with PySpark for reading, writing, and processing data in Databricks environments. From handling various file formats to seamlessly integrating with external data sources including SQL Server, PySpark empowers users to efficiently manage and analyze data at scale.
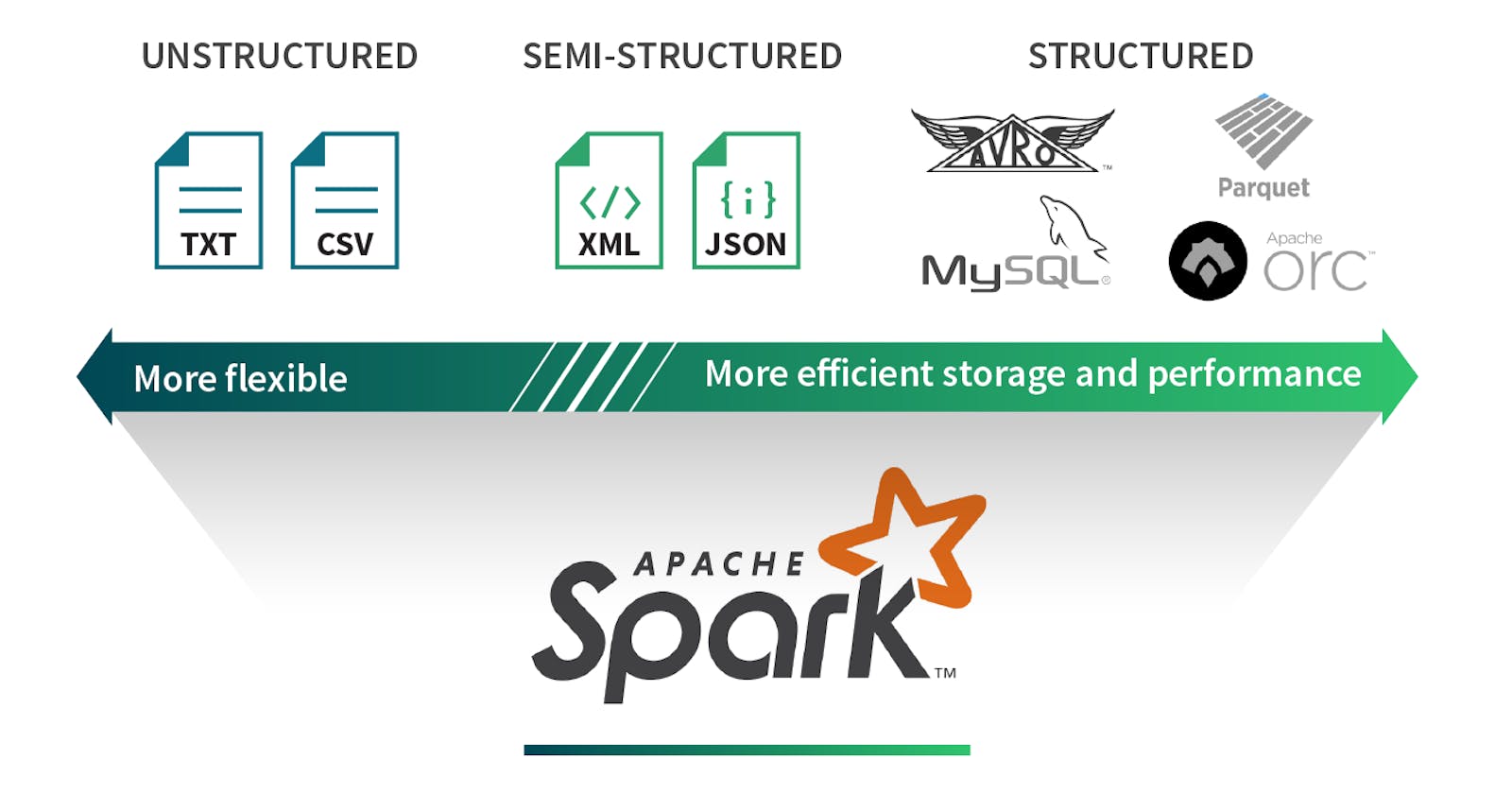
Let’s have a brief about each data format:
Structured data:
An Structured data set is a set of data Data that is well organized either in the form of tables or some other way is a structured data set. This data can be easily manipulated through tables or some other method. This kind of data source defines a schema for its data, basically this data stored in a rows and columns which is easy to manage. This data will be stored and accessible in the form of fixed format.
For example, data stored in a relational database with multiple rows and columns.
Unstructured data:
Unstructured data set is a data has no defined structure, which is not organized in a predefined manner. This can have Irregular and ambiguous data.
For example, Document collections, Invoices, records, emails, productivity applications.
Semi-structured data:
Semi-structured data set could be a data that doesn’t have defined format or defined schema not just the tabular structure of data models. This data sources structures per record however doesn’t necessarily have a well–defined schema spanning all records.
For example, JSON and XML.
Supported file formats
Text: A basic file format where each line represents a record, suitable for simple data storage and processing tasks.
CSV (Comma-Separated Values): Widely used for tabular data storage, CSV files separate values with commas, making them easily readable and compatible with many applications.
JSON (JavaScript Object Notation): Ideal for semi-structured data, JSON organizes data in key-value pairs, providing flexibility and ease of use for representing complex structures.
Parquet: A columnar file format optimized for big data processing, Parquet stores column values together, enabling efficient compression and query performance, particularly for analytics workloads.
ORC (Optimized Row Columnar): Similar to Parquet, ORC is a columnar storage format designed for fast reads and efficient compression, making it suitable for data warehousing and analytics.
SequenceFile: A flat file format containing binary key-value pairs, SequenceFile offers splittable storage and compression support, commonly used in Hadoop ecosystems.
Avro: A compact, efficient binary format for serializing data, Avro supports schema evolution and provides fast writes, making it well-suited for data interchange and messaging systems.
Supports reading JSON, CSV, XML, TEXT, BINARYFILE, PARQUET, AVRO, and ORC file formats(Excel, Delta).
Why do we need different file formats?
Each file format is suitable for specific use-case. Using correct file format for given use-case will ensure that cluster resources are used optimally.
By using different file formats based on your specific use cases and requirements, you can optimize data storage, processing, and accessibility. Each file format offers distinct advantages in terms of performance, compatibility, and data organization, allowing you to tailor your data storage strategy to meet the needs of your business and analytical workflows.
Code Examples for Reading and Writing Various File Formats in PySpark:
Reading & Writing CSV file:
PySpark supports reading a CSV file with a pipe, comma, tab, space, or any other delimiter/separator files.
To import a CSV file into a PySpark DataFrame, we have two options: csv("path") or format("csv").load("path") methods of DataFrameReader. These methods require a file path as input. When utilizing format("csv"), we can specify data sources using their fully qualified names, though for common formats like CSV, JSON, or Parquet you can simply use their short names.
#Using spark.read.csv() with Default Options:
df = spark.read.csv("path/to/file.csv")
# Here I'm reading CSV file Databricks File System (DBFS)
df = spark.read.format("csv").load("dbfs:/FileStore/datasets/netflix_titles.csv")
df = spark.read.csv("path1,path2,path3")
df = spark.read.format("csv")\
.option("delimiter", ",") \
.option("header", "true")\
.option("inferSchema", "true")\
.load("dbfs:/FileStore/datasets/netflix_titles.csv")
df = spark.read.csv('dbfs:/FileStore/datasets/netflix_titles.csv', inferSchema = True, header =True)
Delimiter: Specifies the character used to separate fields in the CSV file. In this case, the delimiter is set to ",", indicating that commas are used to separate values in each row. .option("delimiter", "|") , .option("delimiter", "\t") , .option("delimiter", " ")
Header: Indicates whether the first row of the CSV file contains column names. Setting "true" means the first row is treated as the header, and column names will be inferred from it.
InferSchema: Directs Spark to automatically infer the data types of each column in the DataFrame based on the content of the CSV file. When set to "true", Spark will analyze a sample of the data to determine the appropriate data types for each column.
Reading CSV files with a user-specified custom schema
from pyspark.sql.types import *
# StructType, StructField, StringType, IntegerType
# defining Schema
custom_schema = StructType([
StructField("Name", StringType(), True),
StructField("Age", IntegerType(), True),
StructField("City", StringType(), True)
])
df = spark.read.schema(custom_schema).csv("path/to/file.csv")
Write PySpark DataFrame to CSV file
df.write.option("header",True).csv("/tmp/path/to/write/data")
df2.write.format("csv").mode('overwrite').save("/tmp/spark_output/zipcodes")
PySpark DataFrameWriter also has a method mode() to specify saving mode.
overwrite: This mode overwrites the destination Parquet file with the data from the DataFrame. If the file does not exist, it creates a new Parquet file.
append: This mode appends the data from the DataFrame to the existing file, if the Destination files already exist. In Case the Destination files do not exists, it will create a new parquet file in the specified location.
ignore: If the destination Parquet file already exists, this mode does nothing and does not write the DataFrame to the file. If the file does not exist, it creates a new Parquet file.
error or errorIfExists: This mode raises an error if the destination Parquet file already exists. It does not write the DataFrame to the file. If the file does not exist, it creates a new Parquet file
Reading & Writing JSON file:
PySpark SQL provides read.json("path") to read a single line or multiline (multiple lines) JSON file into PySpark DataFrame and write.json("path") to save or write to JSON file.Usingspark.read.json()with Default Options:
df = spark.read.json("path/to/file.json")
#Loading Multiple Files:
df = spark.read.json(["path/to/file1.json", "path/to/file2.json"])
Specifying MultiLine Option for Nested JSON:
df = spark.read.option("multiline", "true").json("path/to/file.json")
The .option("multiline", "true") configuration is used when dealing with JSON files that contain multiline records or nested JSON structures. By default, PySpark assumes that each line in the JSON file represents a separate JSON object.
Specifying Custom Schema:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
custom_schema = StructType([
StructField("Name", StringType(), True),
StructField("Age", IntegerType(), True),
StructField("City", StringType(), True)
])
df = spark.read.schema(custom_schema).json("path/to/file.json")
Write PySpark DataFrame to JSON file
df.write.mode('Overwrite').json("/tmp/spark_output/zipcodes.json")
What if my JSON data is not in a file but stored in a variable?
If your JSON data is stored in a variable, you can use the spark.read.json() method with the jsonRDD method. For Example:
json_object = ‘{“name”: “Cinthia”, “age”: 20}’
df = spark.read.json(spark.sparkContext.parallelize([json_object]))
Reading & Writing Parquet file:
# Read parquet file using read.parquet()
parDF=spark.read.parquet("/tmp/output/people.parquet")
# for delta files
delta_df = spark.read.format('delta').load(path='dbfs:/mnt/HRM_3000/flat_files/customers_delta/')
# Using append and overwrite to save parquet file
df.write.mode('append').parquet("/tmp/output/people.parquet")
df.write.mode('overwrite').parquet("/tmp/output/people.parquet")
Reading & Writing AVRO file:
# Reading AVRO file
avro_df = spark.read.format('avro').load(path='dbfs:/mnt/HRM_3000/flat_files/customers.avro')
# writing or saving df as AVRO file
avro_df.write.format('avro').saveAsTable("HRM_3000_Customers_AVRO_PY")
Reading & Writing Excel file:
Using pandas:
Let’s see with an example, I have an excel file with two sheets named 'Technologies' and 'Schedule'.
import pandas as pd
# Read excel file with sheet name
dict_df = pd.read_excel('c:/apps/courses_schedule.xlsx',
sheet_name=['Technologies','Schedule'])
Using Pyspark com.crealytics.spark.excel
To use the com.crealytics.spark.excel package in your Spark applications, you typically need to include it as a dependency in your project and ensure that it's available on your Spark cluster at runtime.
excel_df = spark.format('com.crealytics.spark.excel').\
option("header", True).\
option("inferSchema", True).\
load("dbfs:/mnt/HRM_3000/flat_files/customers.xlsx")
Reading data from SQL server:
This code snippet connects Apache Spark with a Microsoft SQL Server database, specifically accessing the "SalesLT.Customer" table. It utilizes JDBC connectivity, with provided credentials for authentication, to seamlessly extract data into a Spark DataFrame named "sample_customer". This enables streamlined integration of SQL Server data into Spark-based analytics workflows, facilitating efficient data processing and analysis within the Spark environment.
# JDBC driver class for SQL Server
driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
database_host = "sample-dbserver.database.windows.net" # hostname of your SQL Server instance.
database_port = "1433" # update if you use a non-default port
database_name = "Sample-db"
table = "SalesLT.Customer"
user = 'useradmin'
password ='Sample@1234'
# This line constructs the JDBC URL using the provided connection details
url = f"jdbc:sqlserver://{database_host}:{database_port};database={database_name}"
sample_customer = (spark.read
.format("jdbc")
.option("driver", driver)
.option("url", url)
.option("dbtable", table)
.option("user", user)
.option("password", password)
.load()
)
Saving DataFrame as JDBC Table in Apache Spark
With Apache Spark's JDBC connectivity, it's easier than ever to save your DataFrame directly into a JDBC-compatible database table.
# to write into Write data with JDBC
(employees_table.write
.format("jdbc")
.option("url", "<jdbc_url>")
.option("dbtable", "<new_table_name>")
.option("user", "<username>")
.option("password", "<password>")
.save()
)
# "<new_table_name>" name of the new table where you want to save the DataFrame.
Key Takeaways:
File Format Flexibility: PySpark provides extensive support for reading and writing various file formats, including CSV, JSON, Parquet, Avro, Excel and more. Whether your data is structured, semi-structured, or unstructured, PySpark offers the tools to handle it effectively.
Efficient Data Retrieval: When working with file formats like Parquet, PySpark leverages schema preservation and columnar storage to optimize data retrieval and processing. This results in faster query execution and improved performance for analytical workloads.
Seamless Integration with SQL Server: PySpark's JDBC connectivity allows for seamless integration with external data sources like SQL Server. By simply specifying the JDBC URL, table name, and authentication credentials, users can read and write data between Spark DataFrames and SQL Server tables with ease.
Scalable Data Processing: With PySpark running on Databricks, users can leverage the scalability and distributed processing capabilities of Spark to handle large-scale data processing tasks. Whether it's ingesting data from multiple sources or performing complex analytics, PySpark provides the scalability and performance needed for modern data workflows.
conclusion
PySpark on Databricks offers a powerful platform for data engineers, data scientists, and analysts to efficiently read, write, and process data from a variety of sources. By harnessing the capabilities of PySpark and Databricks, organizations can unlock new insights and drive innovation in their data-driven initiatives.
Stay Connected
Stay tune for more insightful discussions and Feel free to share your thoughts in the comments! We're also eager to hear what topics you'd like us to cover in our upcoming articles.
Until then, keep exploring, practicing, and expanding your knowledge. The world of databases awaits your exploration!